



目录
- 什么是数据库查询优化?
- 影响查询优化的因素
- 优化策略概述
- 查询优化的总体思路
- 语义优化 -- 内容等价性
- 语法优化(逻辑层优化)---语法等价性
- 执行优化(物理层优化)
- 查询优化在DBMS中的位置
- 逻辑查询优化
- 关系代数
- 优化示例
- 关系代数操作次序交换的等价性
- 明确定义关系代数的等价性
- 等价定理
- 基于关系代数的查询优化算法及示例
- ==关系代数优化算法:==
- 算法应用示例
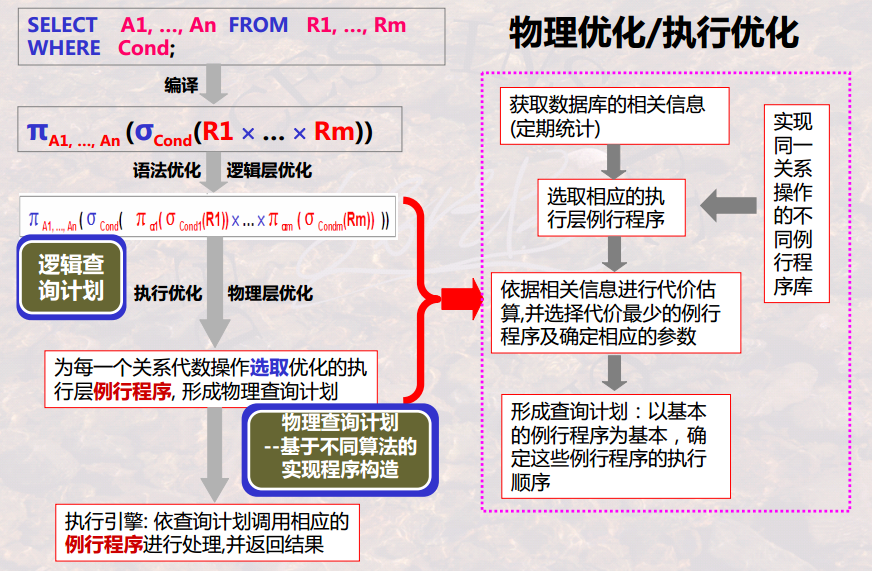
- 物理查询优化
- 为什么使用物理查询优化?
- 物理查询运算符
- 获取关系元组的操作
- 关系操作的各种实现算法
- DBMS如何衡量物理查询计划的优劣?
- 代价估算
- 对投影运算进行代价估算
- 对选择运算的代价估算
- 连接运算的代价估算
什么是数据库查询优化?
计算机科学家们,一直在追求着一些较为通用的目的,比如:
1.通过计算机去解决更多的问题
2.通过计算机去更快的解决问题
而数据库查询优化的目的,更多服务于后面的这个目的,更快的进行查询,快速响应查询结果。
影响查询优化的因素
而在数据库查询中,哪些因素影响着查询的效率呢?
1.计算的数据量。数据量越大,一般计算的次数越多,计算的时间也越长。
2.IO。这也和第一条有关,往往数据量越大,需要的存储空间越大(这里认为数据库中的数据是存在硬盘中的),所以IO的开销越大。
为了进一步深入理解这个问题,我们引入一个简单的例子:
- 该例子从关系代数角度进行讲解。
- Student * SC * CourseStudent?SC?Course最先进行计算,然后后续的计算都建立在此计算结果之上。即,随后的选择操作将会建立在巨大的数据量之上,这计算是非常耗时的。
【一个经验】大数据量如果经过计算步骤越多,那么越耗时。所以,如果能够在等价情况下,在计算早期将数据量降下来,那么将大大提升查询速度。

下面给出了,针对上面的情况的一些等价的关系代数式,这些关系代数将数据量在早期将量降了下来,从而使得:
- 在笛卡尔积之前将数据量降了下来,从而使得笛卡尔积后,数据量不会太大。
- 之前的巨大数据量,不会出现在任何一个步骤,大大节省了计算时间。

优化策略概述

查询优化的总体思路

语义优化 – 内容等价性
本文章中暂且不深入探讨此方面的内容。

语法优化(逻辑层优化)—语法等价性
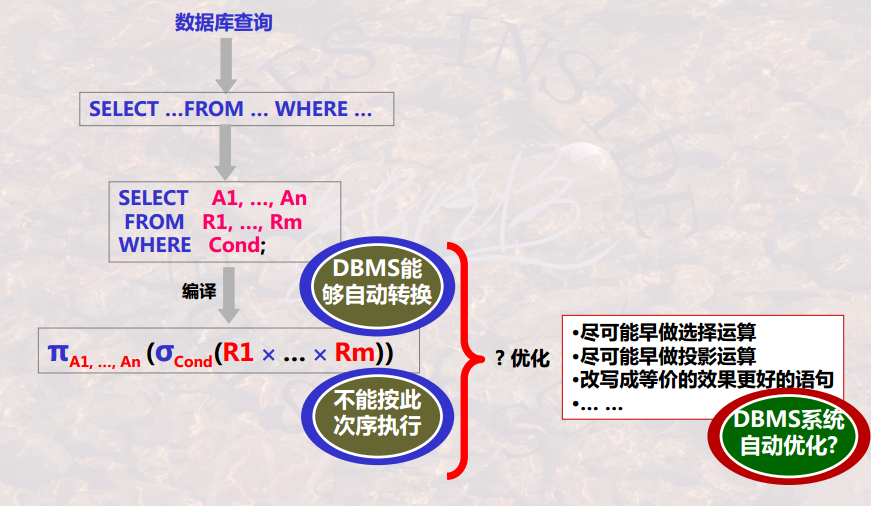

执行优化(物理层优化)
查询优化在DBMS中的位置
- 蓝色虚线部分对应着查询优化。

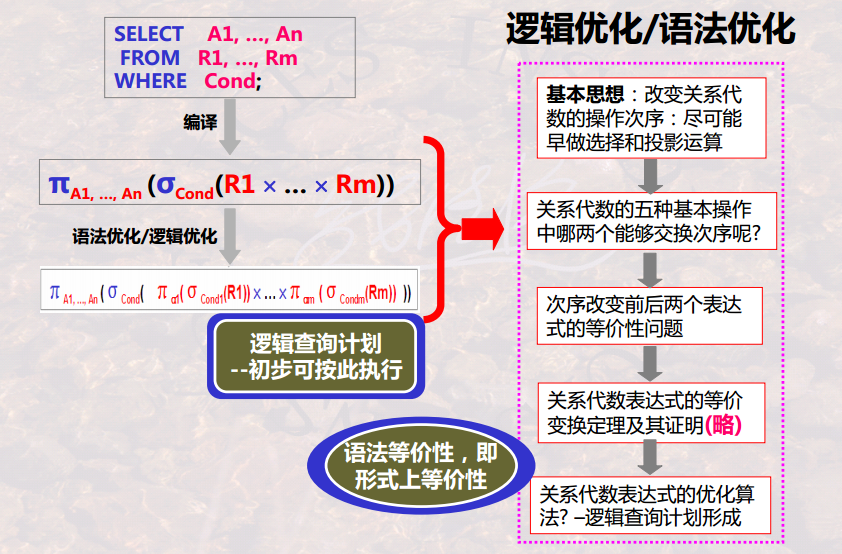
逻辑查询优化
基本思想:
【次序的重要性】关系代数的形式,影响着计算的次序,而次序又会影响着每一步的计算量,以及总体计算量。
【2个明星操作】改变关系代数的操作次序:尽可能早做选择 和投影运算。
【为何提早进行这2个操作:选择 & 投影】
【基本原因】 这些操作能够在早期将数据量降下来,从而避免较多的数据量流入后续步骤中,从而使得大数据量能够在早期计算中降下来。
举个简单的例子:100万条的数据量,情况1:经过5个步骤才降下来,最终得到结果;情况2:100万的数据量在第一步降到了1万,随后经过4个步骤。情况2明显总的计算量要比情况1少。
【投影如何降数据量?】一个表有100个维度,有100万条记录,而你只需要2个维度。投影操作将数据量 变为 : 2维 * 100万。
【选择如何降低数据量?】一个表有100个维度,有100万条记录,而你只需要其中的1万条记录。选择操作将数据量变为: 100维 * 1万。
其它关系操作:
对数据量的降低没有如此立杆见影。
总体思路:
- 【次序很重要】同样的语义表达,在关系代数中往往有 多种形式,这些形式最终获得的结果是相同的。但其反映的内部计算过程却是不同的,而计算过程又是和计算机的计算量紧密结合的,因而计算的次序安排是逻辑优化的本质。
- 【等价定理对于次序很重要】定理给了关系代数形式转化的机会,使得关系代数的次序可以调节。
关系代数
【更新中。。。】为何需要关系代数?(简单论述代数的作用)
(论述关系理论的作用)
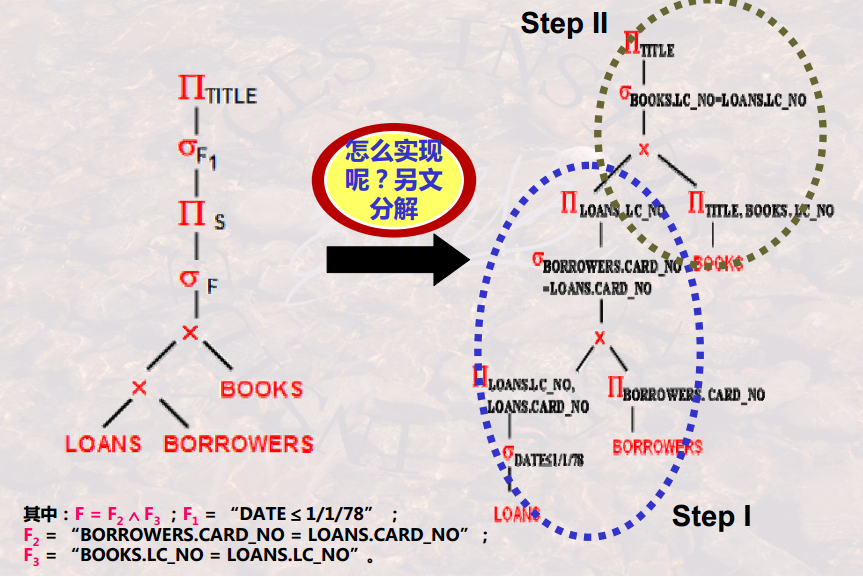
优化示例
在讲解示例的同时,说明相应的逻辑优化策略。
考虑一个图书管数据库:

【查询需求1】:
- 【步骤】sql语句最先被识别转化成关系代数,随后将代数转化为树结构(语法树)。
很多优化步骤都是在遍历语法树的过程中进行的,简单来说就是:树的遍历 + 结点操作规则(如关系代数等价定理)。(理论知识可参考编译原理部分)
- 【优化的体现】(1)在关系代数层面,是操作次序的变化;(2)从语法树角度,优化就是结点的等价移动。

逻辑层的优化策略:

优化后的效果:
- 【总体】这里的优化,是将选择、投影操作尽量向树下移动。为了使其能够向下移动,有时候会增加一些投影等步骤。
- 【选择涉及到一个表】直接向下移动到最靠近相应表的地方。如,借出时间作为条件时,可以向下直接移动到LOAN结点的上一层。
- 【选择涉及多个表】将可拆解的独立的条件,进行拆解,然后各自按照上一个准则进行下移。
- 【投影】投影一般是可以直接下移到表附近的,但是有时候投影涉及到的维度比较少,而中间某个过程可能使用投影之外的维度。因此,在投影下移的时候,必须把中间过程中用到的维度积累起来,最终移动到表的上一层。
关系代数操作次序交换的等价性
前面提到了关系代数的操作次序,能够影响计算量,查询的速度。为此,我们需要将关系代数进行等价变换,从而使得计算机执行关系代数时的耗时最小。
而变换是需要等价规则/定理作为支撑,本部分内容主要介绍等价变换定理。
【备注】构建一个系统之后,准则之后,我们根据现实中的实际的情况,在规则中引入相应的定理,以此能够使得一个代数转化成我们期待的代数。
思考:

明确定义关系代数的等价性
从结果集合的角度,定义等价性。
根据这个定义,你能够通过定义去证明后面的等价定理。

等价定理
定理L1:

定理L2:
- 通过不同的结合次序,能够使得中间结果(中间产生的数据量)降低,从而使得整个过程中总体的数据量降低。
- 【简单的例子】 积运算为例,现在有3个表,其中t1有20条记录,t2有30条记录,t3有100条记录。3个表求笛卡尔积。
情况1:
【(t1 \ imes t2) \ imes t3(t1×t2)×t3】计算分为两个步骤:(1)t1 \ imes t2t1×t2 产生了600的数据量;(2)与t3求积,产生了60000的数据量。
情况2:
【t1 \ imes (t2 \ imes t3)t1×(t2×t3)】计算分为两个步骤:(1) t2 \ imes t3t2×t3 产生了3000的数据量;(2) 与t1求积,产生了60000的数据量。
【结论】虽然情况1与情况2中的第2步计算产生了相同的数据量,然而在第1步中却产生了不同的数据量。(数据量上升的越早,中间产生的代价越多)

定理L3:
- 【从左到右看公式】能够减少一次投影操作。如果每次投影需要遍历1次表的话,那么左边的公式需要扫描2次表,而右边的公式需要扫描1次表。
- 【从右向左看公式】将投影扩展,分解为两次,从而使得投影维度多的那次可以向语法树的下层移动。(因为右边的投影可能因为,在下移后,出现某些维度被过滤掉,而这些维度,正好要在中间某个步骤用)

定理L4:
- 解释类似于定理L3.

定理L5:

定理L6:

定理L7:

定理L8 & 定理L9:

定理L10:

其它思考:

基于关系代数的查询优化算法及示例
关系代数优化算法:
- 【两大步骤】算法可以分为两大步骤:(1)遍历树,结点变换;(2)分组。

算法应用示例
==待优化的结构==

【优化步骤1】选择操作下移:

【移动步骤2】投影移动:
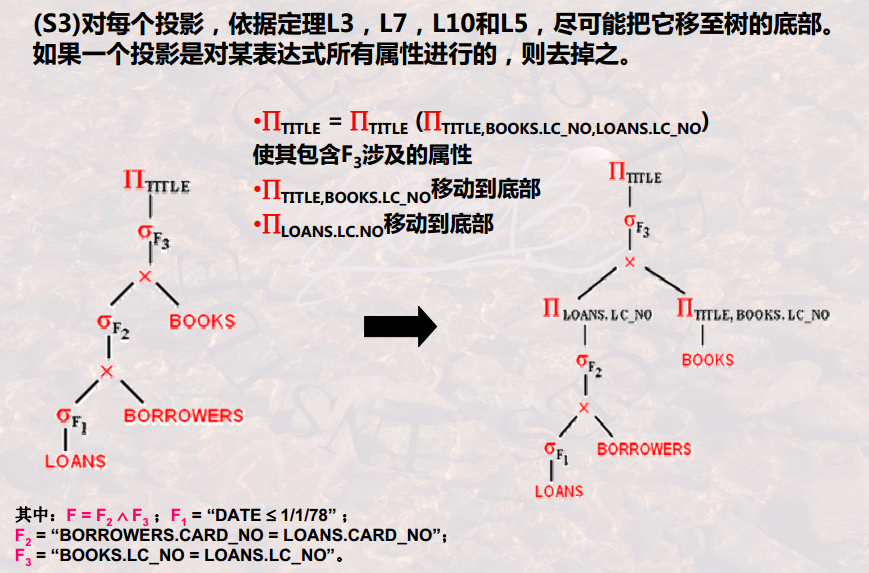

【为执行做准备】分组:
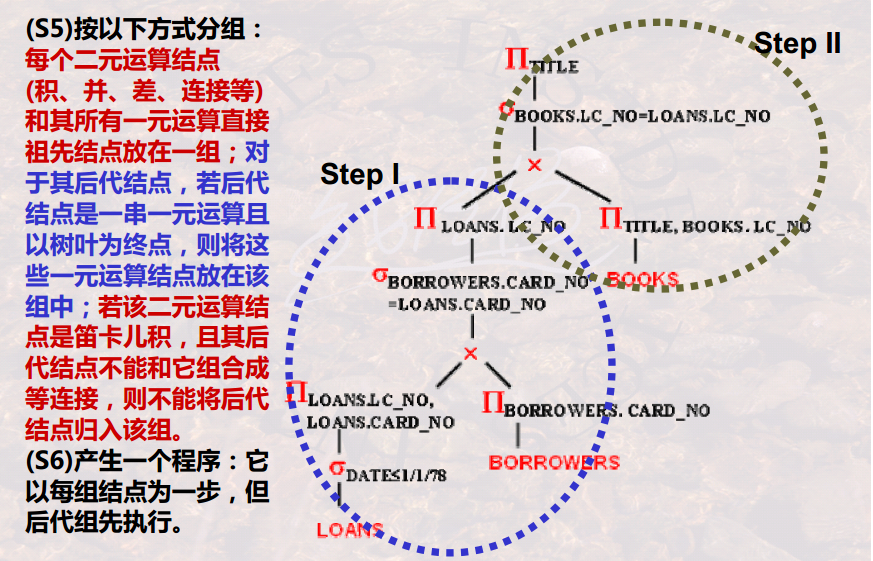
思考:(复杂sql的优化)

物理查询优化
前面从概念上(关系代数角度)进行了优化,但关系代数需要通过计算机层面的具体的算法进行实现。更细节一点来说,关系代数的每一步,都对应着相应的物理计算,而这些物理计算往往存在多种算法,比如说某表具有索引辅助结构,并且关系代数中某部分中含有走索引的条件,那么执行时,一般会采取索引扫描算法。没有索引,则可能走一趟扫描算法等算法。
为什么使用物理查询优化?
- 【基本目标】物理查询优化的主要目标在于,使得IO尽量降低,使得计算尽量减少。
- 【具体表现】表空间扫描范围尽量少,尽量合并能够一起的计算(如,一趟扫描中做多件事情)。

物理查询运算符
获取关系元组的操作

关系操作的各种实现算法

DBMS如何衡量物理查询计划的优劣?

依据什么信息来计算这些方案的上述各种指标呢?
- 【数据字典】数据字典中包含数据库的模式信息以及部分统计信息(比如,如下图的统计信息)。

如何收集统计信息?

代价估算
代价估算,决定了选择关系代数某部分采用哪种计算方法。
结合前面的衡量指标理解本部分。

对投影运算进行代价估算

对选择运算的代价估算


复杂选择运算:
- 利用关系代数定理,将关系代数进行拆解。

- 逐步从里向外进行估算。(相当于前面两个估算示例相结合)

复杂的或运算估计:
- 【概率工具】此处的估算,引入了概率工具。首先计算出同时不满足C1和C2的概率,然后让1减去前面的结果,得到满足C1或C2的 概率。最后估算涉及到的数量。


连接运算的代价估算
- 再次利用概率工具。
- 先求得笛卡尔积,然后连接运算的结果一定是笛卡儿积的子集合。
- 下面的关键问题在于如何估算这个子集合。这里再次运用了概率工具以及大量的假设,通过引入这些合理的假设,使得连接运算的估算成为可能。这里就两个表具有某个相同Y值得概率进行了假设,认为其和V(R,Y)或V(S,Y)有直接的关系。这里不再是仅仅是假设在一个表中出现不同值得概率是相等的,而是假设了更多的内容,即两个表中出现某个相同值得概率是相等的。

文章来自我的CSDN博客:
【学习笔记】数据库基础 - 查询优化



